はじめに
ジャパニーズカルチャーと言っても過言ではない、ライトノベル。 そこで今回は、流行りのライトノベルにはどのような特徴があるのかを調べてみました。
- はじめに
- 使用した技術
- 方向性の確認
- ライトノベルのランキングサイトを決めて、そこからHTMLを取得する
- Beautiful Soup でHTMLを解析し、あらすじ部分のタグを取得する
- あらすじ部分を取得し、textファイルとして保存する
- 保存したtextファイルを整形する
- WordCloudで可視化してみる
- 参考文献
- おわりに
使用した技術
- スクレイピング
- Beautiful Soup
- Requests
- WordCloud
方向性の確認
今回行いたいことは、大規模な調査(データ収集や加工)ではないです。
とりあえず、流行りのライトノベルの情報を数十作品ほど集めて、その作品のあらすじからどんな傾向があるのか大まかにつかむことを到着地点とします。
そこで、以下の手順で進めていきます。
- ライトノベルのランキングサイトを決めて、そこからHTMLを取得する
- Beautiful Soup でHTMLを解析し、あらすじ部分のタグを取得する
- あらすじ部分を取得し、textファイルとして保存する
- 保存したtextファイルを整形する
- WordCloudで可視化してみる
ライトノベルのランキングサイトを決めて、そこからHTMLを取得する
今回ライトノベルのランキングをどこから引っ張ってくるのか迷いました。
結局のところ、ググるとトップページにヒットした以下のサイトを使用することにしました
import time,requests,urllib from bs4 import BeautifulSoup url = "https://bookwalker.jp/rank/ct3/" html = requests.get(url) soup = BeautifulSoup(html.content,"html.parser")
はじめに、必要そうなものをインポートしています。
そして、サイトのURLを指定して、htmlを取得しています。
ここで、実は、print(soup)でサイト情報を出力して見ました(ここでは画面が長くなるので割愛します)
念のため、chromeのディベロッパーツールで検証をし、とりあえずh3タグを指定することにしました。

Beautiful Soup でHTMLを解析し、あらすじ部分のタグを取得する
さて、h3タグを指定することは分かりました。
しかし、これではあらすじがないではないか!?
ということで、多少めんどくさいことになりました。まずは各作品の解説ページへと行く必要があります。そのためにはリンク先へとランディングするために、for 文を使って、aタグを指定することにします。
for a in rank: h3_a = a.find_all("a") print(h3_a)

次に、URLだけを取り出すことにします
そのため、さらにfor文を使い、hrefを指定しました。
for url in h3_a: get_url = url.get("href")

あらすじ部分を取得し、textファイルとして保存する
そして、今回はサイトの構成上、絶対パスとしてそのまま使えるので、楽ですね。
ただし、「#」があることから、一部相対パスを抜き出してしまっています。
そこで、このまま取り出した情報を使うと、明らかにエラーが発生するでしょう。
そのため、エラーを無視するために以下のようにしました。
try: html = requests.get(get_url) time.sleep(3) soup = BeautifulSoup(html.content,"html.parser") except Exception: pass
これで各作品のあらすじが載っているページへとランディングすることができました。
あとは、これまでと同じように、タグを指定して、本文をtextファイルへと保存するだけです。
意外と長いようで短い道のりでした。。。
try: desc_text = soup.find_all(class_="p-summary__text") except Exception: pass
ここでも、エラーが発生したら面倒だったので、あらかじめエラーの無視を指定しています。
意図としては、ランディングページが例えばある作品だけ特設ページへと飛ぶ可能性を予期していました。
要するに、クラス名が異なると困るためです。
texts=[]
for de in desc_text:
texts.append(de.text)
filename = "novel_ranking.txt"
with open(filename, mode="a") as f:
f.write(str(texts))
後は、抜き出したあらすじ部分をtextファイルとして出力するだけです。
ファイルの名前は適当にしました。ランキングのスペルがあっているのか調べていませんが、気にしません(笑)
保存したtextファイルを整形する
まずは、保存したテキストを確認しています。
その際、上述までのテキストとして保存した段階で、リストして保存されてしまっているので、一つの文字列に連結・結合しています。
with open('novel_ranking.txt',mode="r") as f: content = f.readlines() str_content =''.join(content)
 さて、ここからが問題でした。
さて、ここからが問題でした。
まず、改行やよくわからないコードが混ざっており、どのように除去すればよいのかわかりませんでした。
初心者の僕には手に余る難題でしたので、力ずくでreplaceで取り除くことにしました。
なんという馬鹿者であろうか!!!という声が聞こえてきそうですが、初心者なのだから仕方がない。
a = str_content.replace("\\n","") aa = a.replace("\\u3000","") aaa = aa.replace("\'][\'","") aaaa = aaa.replace("\']","") aaaaa = aaaa.replace("[][\'","") filename = "novel_ranking.txt" with open(filename, mode="w") as f: f.write(aaaaa)
とりあえず、ここまでで一回ずつ出力してよくわからない記号がないか目視で確認して行きました。
これが独学の限界なのかもしれないと、思いながら次のステップを考えました。
メンターがいないとやはりきついものがあるなと実感しましたまる
WordCloudで可視化してみる
import MeCab import re import pandas as pd import plotly.express as px from wordcloud import WordCloud tagger = MeCab.Tagger() body = aaaaa parsed = tagger.parse(body).split('\n') parsed[:4]
もろもろ必要そうなツールをインポートしています。
ここでさっそく、メカブの登場です(読み方あっていますよね・・・?)。
とりあえず、改行して区切っています。これは見やすくするためです。
ここで、以下の書籍を参照すると、パースした最後のところはうまく改行できていないということを知りました。
Python 実践 データ加工/可視化 100本ノック
そのため、書籍の通りの対処をしました。 加えて、リストの中にリストが入った状態になっており、データフレームに入れるために、書籍の通りに対処しました。
parsed = parsed[:-2] *values, = map(lambda s: re.split(r'\t|,',s),parsed) # 「python 実践データ加工/可視化 100本ノック」より引用。
続けて、データフレームを整えていきます。
columns = ['表層形','品詞','品詞細分類1','品詞細分類2','品詞細分類3','活用型','活用形','原形','読み','発音'] mecab_df = pd.DataFrame(data = values, columns=columns) # 「python 実践データ加工/可視化 100本ノック」より引用。
そして、ようやくデータフレームを作り、中身をいじっていきます。
まずは名詞と動詞(+名詞あり)のパターンを用意しておきます。それに対して、いらない言葉リストを作って、その言葉たちを取り除くことで調整して行きました。
noun = mecab_df.loc[mecab_df['品詞'] == '名詞'] verb = mecab_df.loc[(mecab_df['品詞'] == '名詞')|(mecab_df['品詞'] == '動詞')] with open('stop_words.txt',mode='r') as f: stop_words = f.read().split() noun = noun.loc[~noun['原形'].isin(stop_words)] verb = verb.loc[~verb['原形'].isin(stop_words)] # 「python 実践データ加工/可視化 100本ノック」より引用。
次に、単語の使用状況を確認して行きました。 10個と20個の2つのパターンでplotlyを用いて可視化してみました。
count = noun.groupby('原形').size().sort_values(ascending=False) count.name = 'count' count = count.reset_index().head(10) fig = px.bar(count, x=count['count'], y=count['原形'], orientation='h') fig.show()
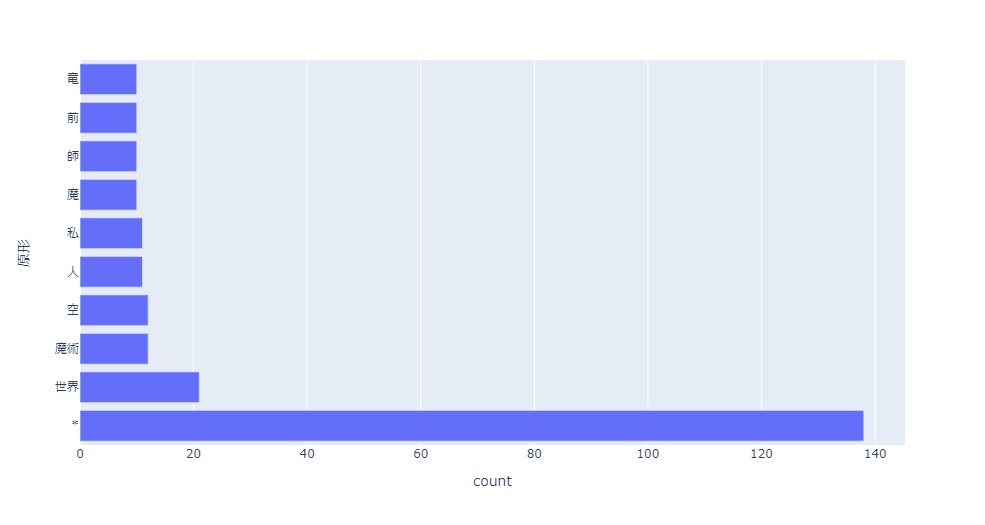

世界、魔術、師、魔と言った中二心をくすぐる言葉が出てきました。
異世界ものが流行っているのかなと、思いました。
てっきり、ラブコメとか恋愛ものが人気なのかなとも思っていたのですが、例えばサンプル数のせいでしょうか。
cloud = WordCloud(background_color="white",font_path=font_path).generate(' '.join(verb['原形'].values)) plt.figure(figsize=(10,5)) plt.imshow(cloud) plt.axis('off') plt.savefig('verb_noun_base.png') plt.show()

てか、個人的には、ロシアとミハイルのワードが気になって仕方ないですね。
例えば、ロシア語を話す(ロシアを題材にしたような)ライトノベルが日本で出回っていることに驚きがありました。
海外の方の作品なのでしょうか、作者のバックグラウンドが気になりました。
……ちょっと、疲れたので、調べるのは諦めます(笑)
参考文献


おわりに
python 使って色々したいがいかんせんメンターなしでは、きついですね。。。