はじめに
前回はコーヒーの種類について産地別に特徴を調べました。
今回はお茶の種類についてまとめていきたいと思います。
行ったこと
大雑把に表現すると以下の流れで、お茶の種類をまとめました。
- 「お茶」AND「種類」でググる
- 一番上にヒットしたサイトを確認し、お茶の種類が載っていることを確認し、スクレイピング
- 若干のデータの整形
コード
サイトからお茶の種類と特徴をスクレイピング
import pandas as pd from bs4 import BeautifulSoup import requests url = "https://chiran-omoiire.com/tashinamu/type" h = requests.get(url) soup = BeautifulSoup(h.content,"html.parser") dff = [] for i in soup.find_all("li"): for ii in i.find_all("h5"): for iii in i.find_all('p'): df = [str(ii.text),str(iii.text)] dff.append(df) pd.DataFrame(dff).to_csv("tea.csv",encoding="utf-8")
はじめに、必要そうなモジュールを呼び出しています。その後、該当のURLを指定しています。
今回はサイトを開くと、欲しい情報が「h5」と「p」タグに入っていたので、それらを指定しています。
実はfor文を繰り返しているのですが、見栄えはあまりよくないです。
ここは、おそらく内包表記で表現できるはずなのですが、勉強不足でそこら辺の理解が伴っていないため、今回は諦めました。
それから、集めた情報を文字列として空のdffというところに収納し、一つのファイル内に行と列を持った形で書き込むためです。
最後に、収納した情報をCSV形式で保存しています。
保存したファイルの中身を表示する
data = pd.read_csv('tea.csv', encoding="utf-8") data
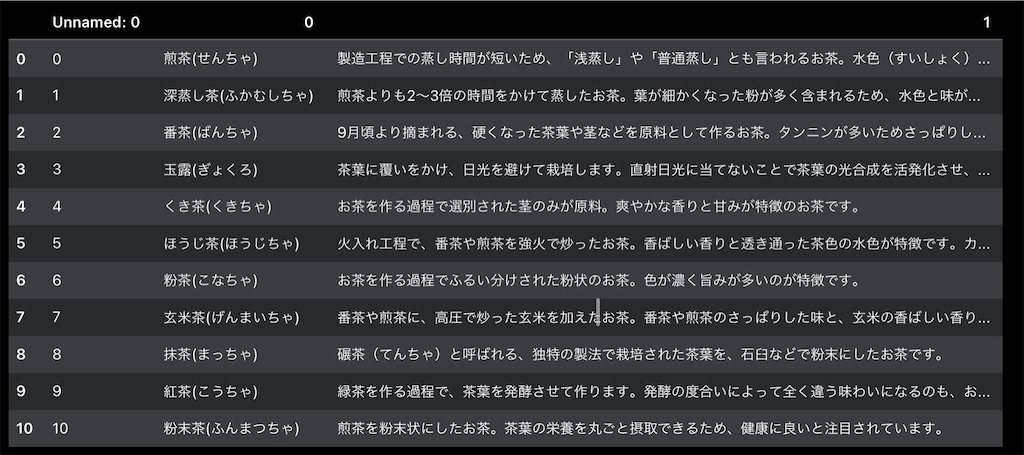
うまく収納されています。
……はい、なんか表が見にくいため、若干修正していきます。
例えばいらない連番や列名の説明がないため、そこら辺を修正していきます。
保存したCSVファイルの列名の変更と連番が載っている列を削除する
import pandas as pd data = pd.read_csv('tea.csv', encoding="utf-8") del data['Unnamed: 0'] dd=data.rename(columns={"0":"お茶の種類","1":"特徴の説明"}) dd.to_csv('tea1.csv',encoding="utf-8") dd

ここでは「Unnamed: 0」という列が邪魔なので削除しています。
その上で、rename()を用いて、列名を変更しています。
最後に、変更後のデータを保存しています。
補足
一つのサイトからしか情報を集めていないため、今回は別のサイトからも情報を集めようとしたのですが、結局うまくいきませんでした。。。
import pandas as pd from bs4 import BeautifulSoup import requests url = "http://shop.chanoma.co.jp/column/kind/kind.html" h = requests.get(url) soup = BeautifulSoup(h.content,"html.parser") dff = [] for i in soup.find_all("h3"): with open("tea3_header.txt","a",encoding="utf-8") as f: f.write(i.text+"\n") for ii in soup.find_all(id = "detail"): for iii in ii.h3.find_next_siblings("p"): df = [str(i.text),str(iii.text)] dff.append(df) pd.DataFrame(dff).to_csv("tea3.csv",encoding="utf-8")
ここでは上述のサイトと同様にお茶の種類とその特徴について書かれた部分をスクレイピングを試みています。
しかし、一つのファイルに列と行を持った状態にうまくできませんでした。そのため、一旦、h3タグをテキストで保存しておきました。
というのも、最初のfor文で取り出したh3タグの情報を収納しようとしても、(pタグの数と合わないからか?)h3タグの情報がうまく列に入ってくれませんでした。
よくわからないので、一度で全てを処理するのは諦めて、後でCSVの方の列を書き換えようと思っています。
おわりに
とりあえず、当初の目的であるお茶の種類を知るということはできたので、個人的には満足しました。
もっとpythonの勉強を頑張って、実務で使えるレベルにしたい!!!
ところでコーヒーメーカーか何がいいのかわからんから、スクレイピングで情報をかき集めようかな。。。。。。